Web scraping 101 With Python

I'm an Embedded system developer and IoT solution architect, PCB Designer
Web scraping Definition
Just like those trendy buzzwords in tech that leaves you wondering, thrilled and fascinated, web scraping was one of those for me. Just as the name implies, web scraping is the process of extracting, some would say mining and parsing out useful information from a webpage through automation.
In this article, we will learn about web scraping and also try scraping a web page. To be able to follow the exercise in this article, you are expected to have basic knowledge of HTML, CSS and Python Programming language.
Web scraping Legality
Hey, I mean I know you are excited and hyped to get started, but you need to know this for sure. There are limitations to what you can scrap on the web. If the webpage requires ReCaptcha, user login or any means of access protection please kindly stay away, you will get into real trouble scraping such web pages.
In other words, you can only scrap webpages that are publicly available out there.
It is important to note that if a website has a publicly available API out there, please kindly use it. Do not scrap their web pages. Also, constantly scraping a web page can cause traffic leading to a poor surfing experience for the target users.
Getting Practical
While they are other tools that can be used to scrape webpages in python, we will be using Beautifulsoup for our exercise. Beautifulsoup is a python library/module that allows developers to extract information from a webpage.
We are going to scrap this Amazon webpage to print the current price of the Roku streaming stick 4K device. And also monitor its price.
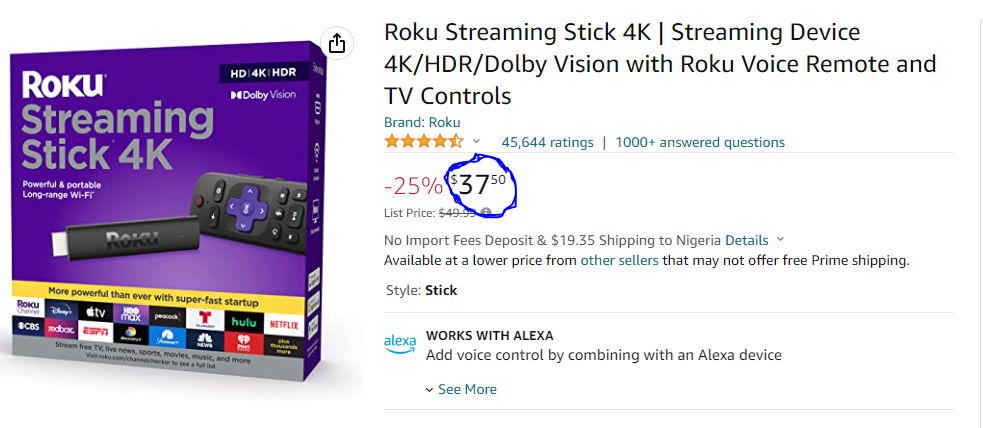
So let us go ahead to write our python program that will extract the price.
# Importing our libraries/modules
from bs4 import BeautifulSoup
import lxml
import requests
# Amazon URL
URL_AMAZON = "https://www.amazon.com/Roku-Streaming-Device-Vision-Controls/dp/B09BKCDXZC/ref=lp_16225009011_1_12?th=1"
# HTTP Header parameters
HEADER = {
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
# HTTP get request
url_resp = requests.get(url=URL_AMAZON, headers=HEADER)
# Making our soup
soup = BeautifulSoup(url_resp.text, "lxml")
# Extracting the first tag with class attritbute "a-price-whole"
roku_curr_price = int((soup.find(class_="a-price-whole")).getText().strip("."))
# printing our price
print(roku_curr_price)
Let us break this code down, for better understanding.
# Importing our libraries/modules
from bs4 import BeautifulSoup
import lxml
import requests
The "import" syntax in python allows us to include the libraries/modules that we intend to work with. "bs4" is a library where the class "BeautifulSoup" exist. The library lxml is going to serve as a Markup language parser, the reason being a website could either be HTML or XML based, lxml supports both so it is safe to use it.
The requests module allows us to make HTTP requests using python.
URL_AMAZON = "https://www.amazon.com/Roku-Streaming-Device-Vision-Controls/dp/B09BKCDXZC/ref=lp_16225009011_1_12?th=1"
# HTTP Header parameters
HEADER = {
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
The "URL_AMAZON" is a constant that holds the URL of Amazon's webpage. The "HEADER" constant is an essential parameter required for most HTTP requests. Generally, HTTP headers contain fields that indicate additional context and metadata about a request or response.
The "Accept-Language" is how we tell the server the language or locale we prefer. While the "User-Agent" is a field that specifies the properties of our machine, this information is used to determine what content to return. Here is a link to read more on User-Agent.
# HTTP get request
url_resp = requests.get(url=URL_AMAZON, headers=HEADER)
What we have done here is to make an HTTP get request to the passed Amazon URL which in turn returns a server response to the variable "url_resp".
It is important to note that the "request.get" method returns a class as a server response. Hence "url_resp" is a class object.
# Making our soup
soup = BeautifulSoup(url_resp.text, "lxml")
# Extracting the first tag with class attritbute "a-price-whole"
roku_curr_price = int((soup.find(class_="a-price-whole")).getText().strip("."))
# printing our price
print(roku_curr_price)
The first line of code creates an instance of the class "BeautifulSoup". The "url_resp.text" is a method in the class object "url_resp" that converts our returned Amazon webpage to a string of characters as this is the format supported by "BeautifulSoup", the second parameter indicates the parser in use, in our case, it is "lxml".
The "soup.find(class_="a-price-whole") " method finds the first specified parameter (i.e. an HTML tag, CSS class or id attribute ) in our downloaded webpage. In our case we are looking for the first class attribute with the name "a-price-whole" as the HTML tag of this attribute holds the price of our Roku streaming stick 4K device. This was concluded after inspecting our Amazon webpage on the browser.
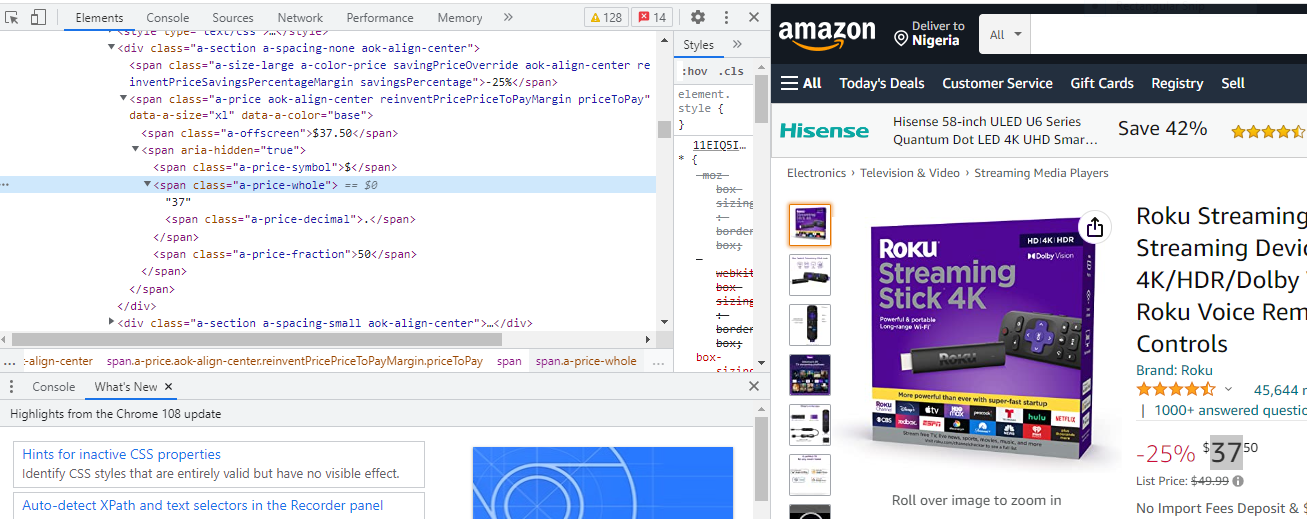
One thing to observe in the above image is that there are a lot of Span HTML tags on our desired webpage, so there is no way we can use only the HTML tag to find and extract the information of our interest, hence the need to use its class attribute.
The .getText() method is to get the exact price figure and not the HTML line of code with the HTML tags attached. The .strip(".") method in python returns a copy of the string by removing both the leading and the trailing characters (based on the string argument passed). At the time of writing this article, the price was returning 37.50, since the cent value did not matter much to me I decided to strip it off. You can play around with this and twerk the code however you want.
The int() syntax was a way to typecast our returned price to be an integer value. You can choose not to do this if you have no intention of carrying out mathematical operations on the price.
The next line of code prints our price on the console.
Let us go ahead and try to compare our returned price with a set value. If the conditions are true we print something on the console or can choose to send ourselves a reminder email to order the product immediately or have it run any condition at all. The email part will not be covered in this article we will only have to print it on the console.
# Importing our libraries/modules
from bs4 import BeautifulSoup
import lxml
import requests
# Amazon URL
URL_AMAZON = "https://www.amazon.com/Roku-Streaming-Device-Vision-Controls/dp/B09BKCDXZC/ref=lp_16225009011_1_12?th=1"
# HTTP Header parameters
HEADER = {
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
# HTTP get request
url_resp = requests.get(url=URL_AMAZON, headers=HEADER)
# Making our soup
soup = BeautifulSoup(url_resp.text, "lxml")
# Extracting the first tag with class attritbute "a-price-whole"
roku_curr_price = int((soup.find(class_="a-price-whole")).getText().strip("."))
# printing our price
print(roku_curr_price)
SET_PRICE = 43
# Compare Set price to returned price
if roku_curr_price <= SET_PRICE:
print("This is the right time to place your order!")
There are other functionalities of the
Wrapping Things Up
# Importing our libraries/modules
from bs4 import BeautifulSoup
import lxml
import requests
import time
# Amazon URL
URL_AMAZON = "https://www.amazon.com/Roku-Streaming-Device-Vision-Controls/dp/B09BKCDXZC/ref=lp_16225009011_1_12?th=1"
# HTTP Header parameters
HEADER = {
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
SET_PRICE = 43
TIME_INTERVAL = 50
def get_curr_price():
# HTTP get request
url_resp = requests.get(url=URL_AMAZON, headers=HEADER)
# Making our soup
soup = BeautifulSoup(url_resp.text, "lxml")
# Extracting the first tag with class attritbute "a-price-whole"
roku_curr_price = int((soup.find(class_="a-price-whole")).getText().strip("."))
# printing our price
return roku_curr_price
def is_price_ok(curr_price):
# Compare Set price to returned price
if curr_price <= SET_PRICE:
print("This is the right time to place your order!")
# you can choose to send your self an email at this point (;
while True:
# get current price from amazon
price = get_curr_price()
is_price_ok(price)
# A little delay before scraping for price again.
time.sleep(TIME_INTERVAL)
We now have a more organized and automated python script. We have added a module named "time" to give us the time-delay functionality. It is advisable to choose a decent time-delay interval in between scraping, this is to avoid generating unnecessary traffic for Amazon.
Key functionalities have been divided and grouped into functions to aid readability.
In our next article, we will be scraping the list of songs and artists in Billboard100 of a given year and will be creating a Spotify playlist with our scrapped data.

